前回はRequests と Beautiful Soupを使ってWebページの特定のタグの情報を読み込んで見ました。
しかし、そのライブラリだけだとWebページ内のテーブルの情報を抜き出すのは大変そうだなあとおもっていました。
そんな中、Pandasというライブラリを使えば簡単にテーブルの情報を抜き出せるようでしたので、トライしてみました。
1.ライブラリの読み込み
まずは必要なライブラリをPyCharmに取り込みます。
今回、Pandasとlxmlを初めてPyCharmで利用するので、以下のように取り込んでいます。
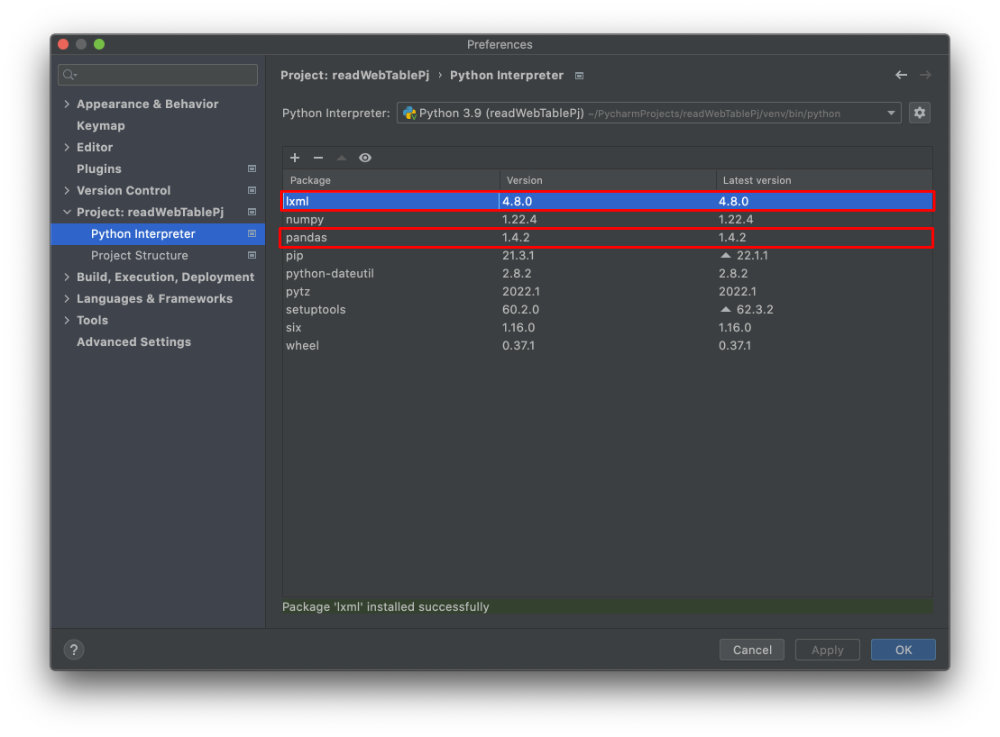
2.プログラミング
そしていつものように^^、おもむろにプログラミングします。
なお、今回スクレイピングしているサイトも、前回同様、私のブログ
https://k2-ornata.com/security-countermeasure/
となっています。
import pandas as pd url = 'https://k2-ornata.com/security-countermeasure/' dfs = pd.read_html(url) # table count print(len(dfs)) # head 5 line print print(dfs[0].head()) # cell[0,0] print print(dfs[0].iat[0,0]) # cell[0,1] print print(dfs[0].iat[0,1]) # first column only print print(dfs[0].iloc[:,[0]])
簡単に内容を説明すると、
最初の3行・・・ライブラリを読み込んだあと、Webページを読み込み、dfsに格納
次の2行・・・Webページ内のテーブルの数を表示
次の2行・・・最初のテーブルdfs[0]の先頭5行を表示
次の2行・・・最初のテーブルdfs[0]のセル[0,0]の内容を表示
次の2行・・・最初のテーブルdfs[0]のセル[0,1]の内容を表示
最後の2行・・・最初のテーブルdfs[0]の1列目[0]を表示
となっています。
そして以下が実行結果です。(見やすくする為に各printの間に1行入れています。)
13
0 1
0 概要 CSPM(Cloud Security Posture Management)クラウドの設定...
1 参考文献 改めて知るCWPP(Cloud Workload Protection Platform)と...
概要
CSPM(Cloud Security Posture Management)クラウドの設定に不備がないかチェックし、不備があれば自動的に修正までしてくれる製品と思われる。CWPP(Cloud Workload Posture Management)オンプレやクラウド上の様々なワークロード(※)における脆弱性管理やセキュリティ保護を行う製品と思われる。両者をどちらもカバーする製品として、パロアルト社のPrisma Cloudがあり、CNSP(Cloud Native Security Platform)と読んでいる。※ワークロードっていう言葉はいつきいてもあまりピント来ませんが、物理マシンや仮想マシン、コンテナ、サーバレスなどを指すらしい。
0
0 概要
1 参考文献
3.Pamdasの使い方
Pandasを使うと今回のように、Webページ内のテーブルの数や、特定のテーブルの情報、さらにその中テーブルの中の特定のセルなどの情報が読み取れるようです。
とりあえず今回使用したものを簡単に説明しておきます。
len(dfs)
dfs の中にWebページ内の全てのテーブル情報が書き込まれ、len()関数を使うことで、そのテーブルの数(Webページに全部で何個テーブルがあるか)をカウントできます。
dfs[テーブル番号]
dfs[テーブル番号]という形で指定することで、ページの先頭から何番目のテーブルの情報かを指定することができます。
dfs[テーブル番号].head()
.head()関数を使うことで、指定したテーブルの先頭から5行目までを取得することができます。
dfs[テーブル番号].iat[行,列]
.iat[行,列]を使うことで、指定したテーブルのどのセルの情報を取得するかを指定することができます。
dfs[テーブル番号].iloc[:,[列]]
.iloc[:,[列]]を使うことで、指定したテーブルの特定の列の情報だけを取得することができます。
なお、”:”の記述はとりあえずおまじないとおもっておけばいいと思います。(あまりよくわかってないのでー。)
4.最後に
過去3回に渡ってPythonを触ってみましたが、Pythonにはいろんなライブラリがあり、それをうまく使えばいろんなことがとても簡単にできるなあと実感しました。
Pythonが人気があるのもわかる気がしますね。
<参考サイト>
・Python, pandasでwebページの表(htmlのtable)をスクレイピング(note.nkmk.me)
https://note.nkmk.me/python-pandas-web-html-table-scraping/
・pandasで任意の位置の値を取得・変更するat, iat, loc, iloc(note.nkmk.me)
https://note.nkmk.me/python-pandas-at-iat-loc-iloc/





コメントを残す