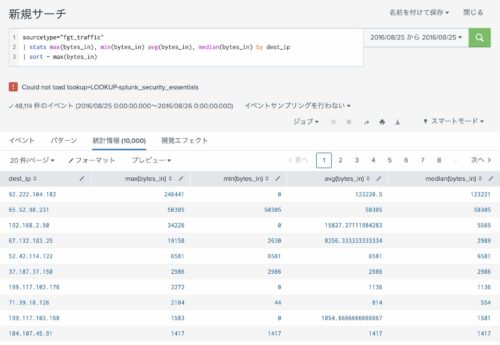
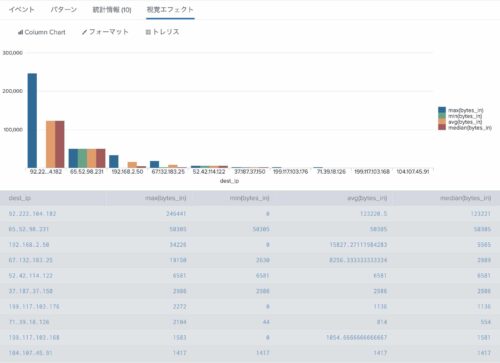
mvcount を利用してマルチバリューデータのフィールドの中に何件のデータが入っているか確認します。
なお、マルチバリュー(Multi-value)とは、1つのフィールドの中に「複数の値」が入っている状態のことです。
たとえば、ip のフィールドの中のデータが [192.168.1.1, 10.0.0.5, 172.16.1.10]となっている場合、ipはマルチバリューだということができます。
mvcountを使ったSPLの書き方
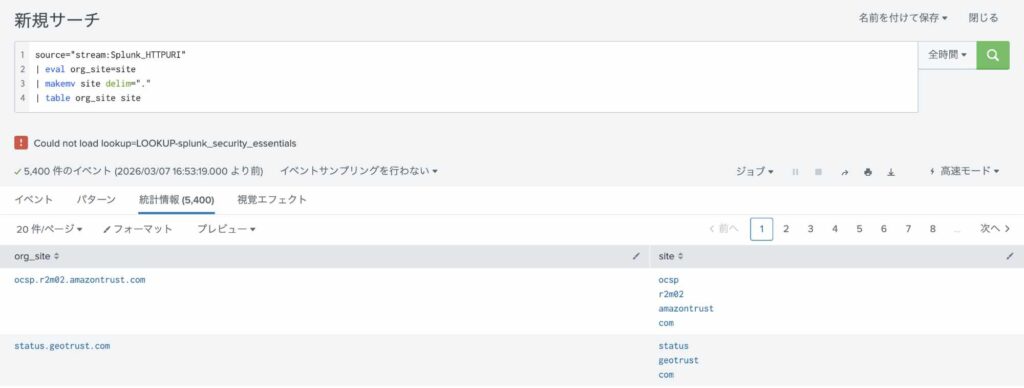
以下のSPLは mvcountマクロを使い、マルチバリューである siteフィールドの中に何件のデータが入っているかチェックし、ダッシュボード上に表示しています。
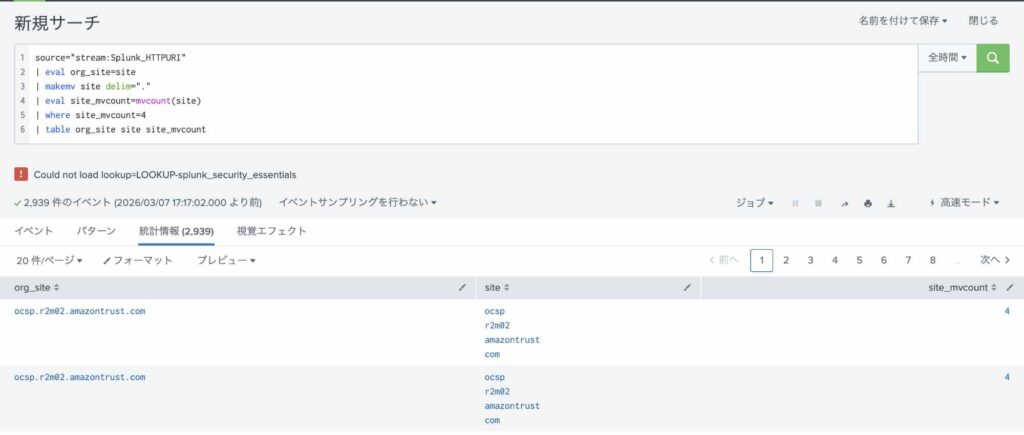
source="stream:Splunk_HTTPURI"
| eval org_site=site
| makemv site delim="."
| eval site_mvcount=mvcount(site)
| where site_mvcount=4
| table org_site site site_mvcount
上記SPLを実際に実行するとこうなります。
参考サイト:
・Splunkでマルチバリューフィールドを扱う (eval関数編)(じゅのぶろ)
https://jnox.hatenablog.com/entry/splunk/eval-multi-value