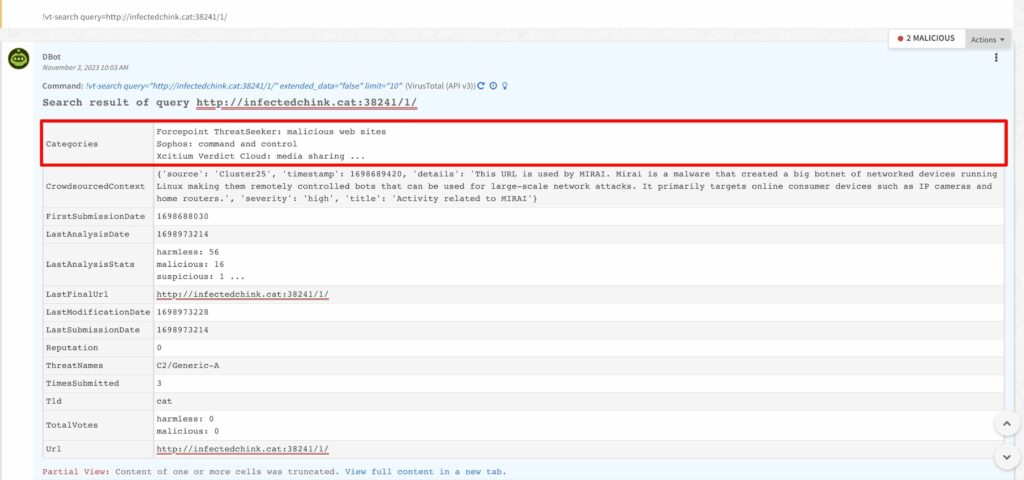
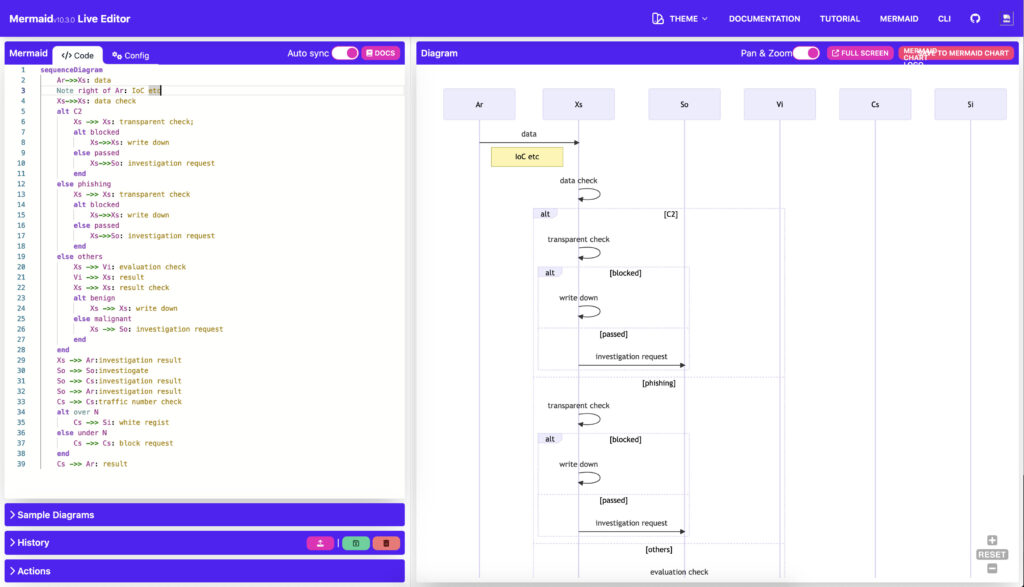
XSOARには Web APIが用意されていて、コマンドプロンプトから以下のようなコマンドを実施すると、”palybookId”で指定したプレイブックを起動したり、”details”で指定した情報をインシデント情報として記録できます。(プレイブックのインプットデータとしても活用可能)
% curl -kv 'https://XX.XXX.XX.X:XXXX/incident' -X POST -H 'Authorization: XXXXXXXXXX' -H 'Accept: application/json' -H 'Content-Type: application/json,application/xml' -d '{"name": "test 20231201","type": "Access","owner": "admin","details": "https://k2-ornata.com/%22,%22playbookId": "59daa471-0cc5-495a-8567-1a252fd020c6"}'
この情報を元に Power Automate for Desktopの「Webサービスを呼び出します」を使って、同じ様に XSOAR にアクセスしてみました。
1.まずはChatGPTに相談
curlのコマンド情報からから Webリスクエストを作成してくれるサイトはいくつかあるようですが、どれも今一つだったので、そういえばと思い ChatGPT に相談してみました。(別のコマンドを相談した時のものですが。)
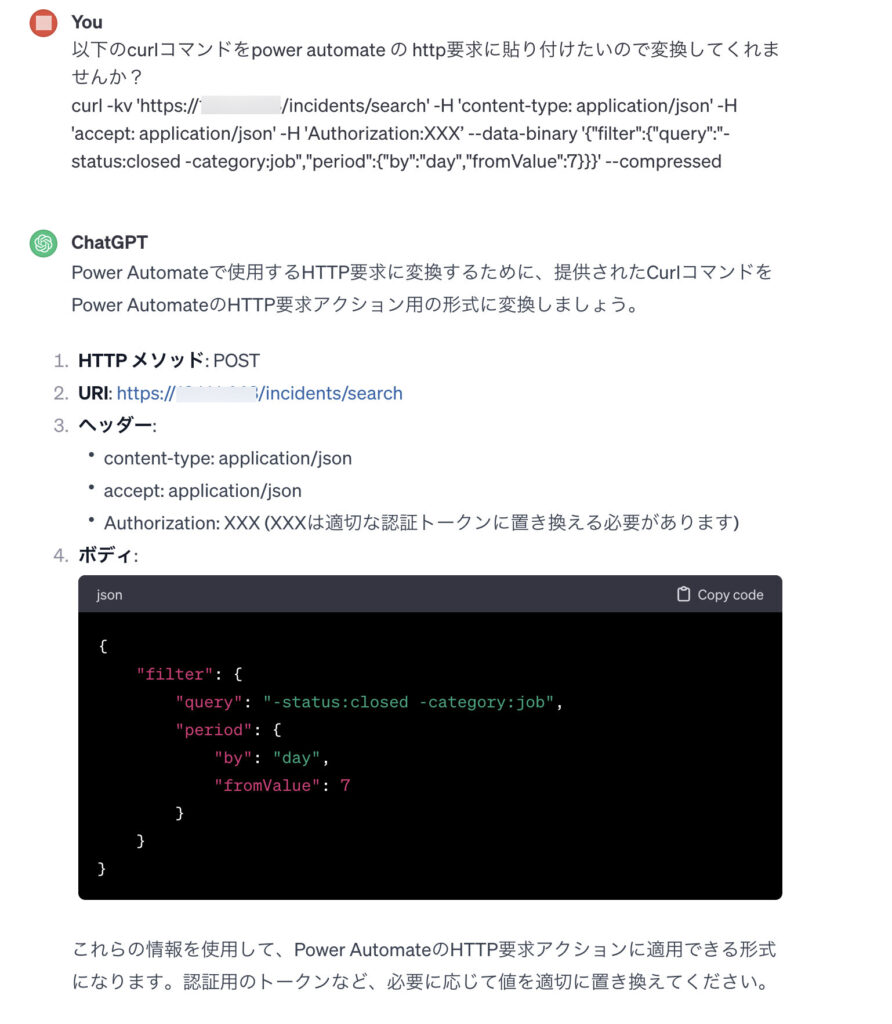
上記は少し違うコマンドについて相談したときのものですが、かなりいい感じで答えてくれていることがわかります。
2.Power Automateを設定
そこで 上記の ChatGPT の回答も踏まえながら、以下の通り各パラメータを設定してみました。
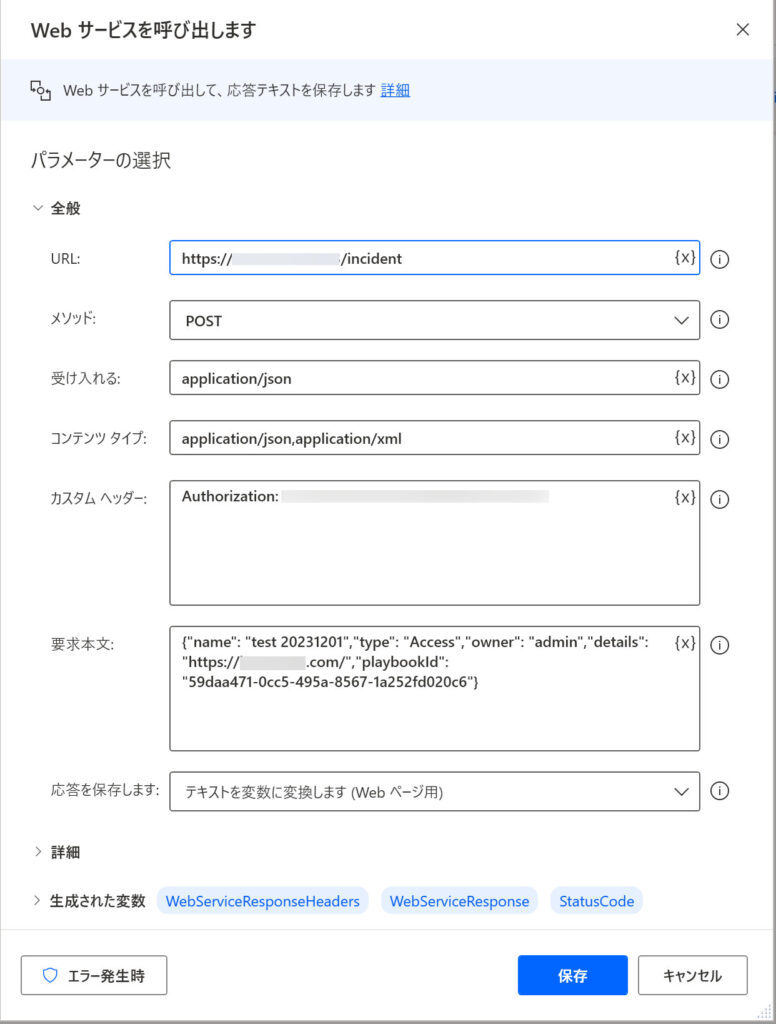
3.レスポンスエラーへの対処(400, 403)
しかしながらすんなりとはいかず、SOARからの以下のようなレスポンスエラーが頻発しました。
{"id":"bad_request","status":400,"title":"Bad request","detail":"Request body is not well-formed. It must be JSON.","error":"unexpected EOF","encrypted":false,"multires":null}
こういったエラーが XSOAR から返ってくるようであれば、以下の3点を見直してみる必要があります。
<正しくWeb APIにアクセスするポイント>
1.Authorization: に認証情報が正しく設定されているか?
2.「要求本文」に記載したデータが正しく JSON フォーマットで描かれているか?
3.「詳細」設定にて以下の図の通り「要求本文をエンコードします」がOFFになっているか?
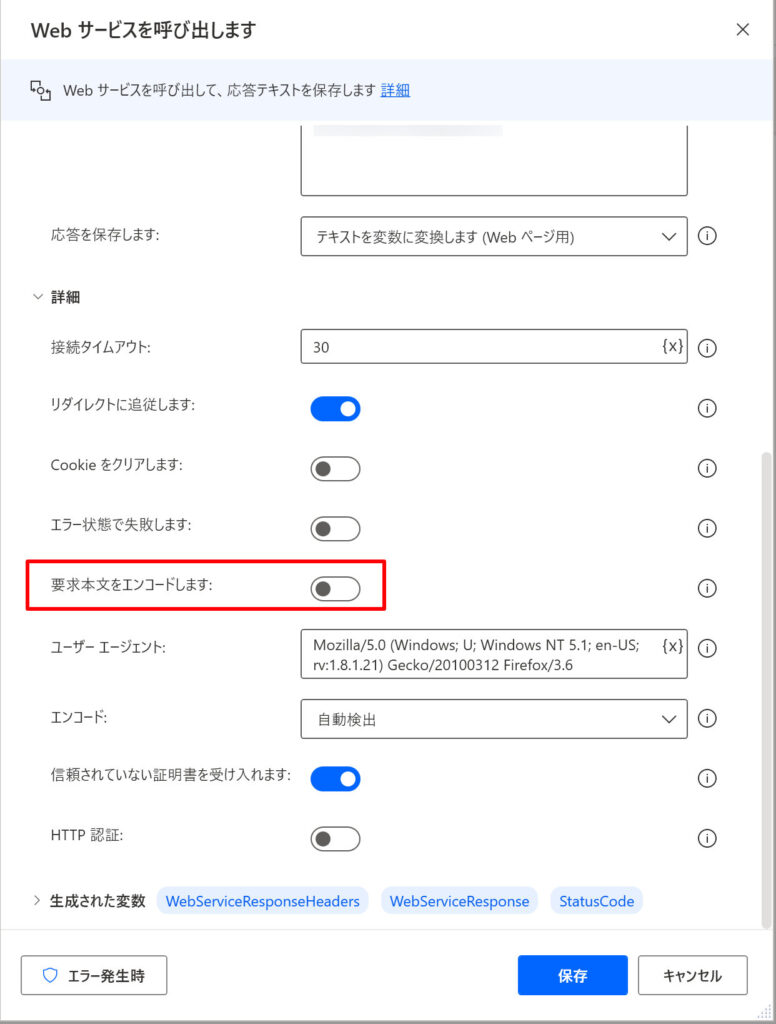
特に2.のJSONフォーマットはかなりシビアな感じなので、念入りに確認する必要があります。たとえば以下のように同じ”でくくっているように見えて実は”になっていたりするので要注意です。
"59daa471-0cc5-495a-8567-1a252fd020c6”
これらを修正することで、ようやく正常に XSOAR にアクセスすることができました。