今までWordPress のテーマとして、Twenty Sixteenを利用してきましたが、最近、ユーザインターフェイスがよりモダンな Twenty Twenty-Fourに変えてみました。
Head, Footer and Post Injectionsを導入する
ところが Twenty Twenty-Four にかえたところ、デフォルトでheader.php を編集する画面がなくなった為、WordPressのプラグイン 「Head, Footer and Post Injections」を使うことにしました。
このプラグインを使えば、ヘッダーに任意のタグを追加するだけではなく、WordPressの全記事に渡って共通の広告を表示させることができます。
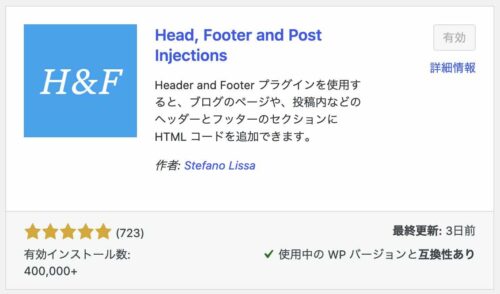
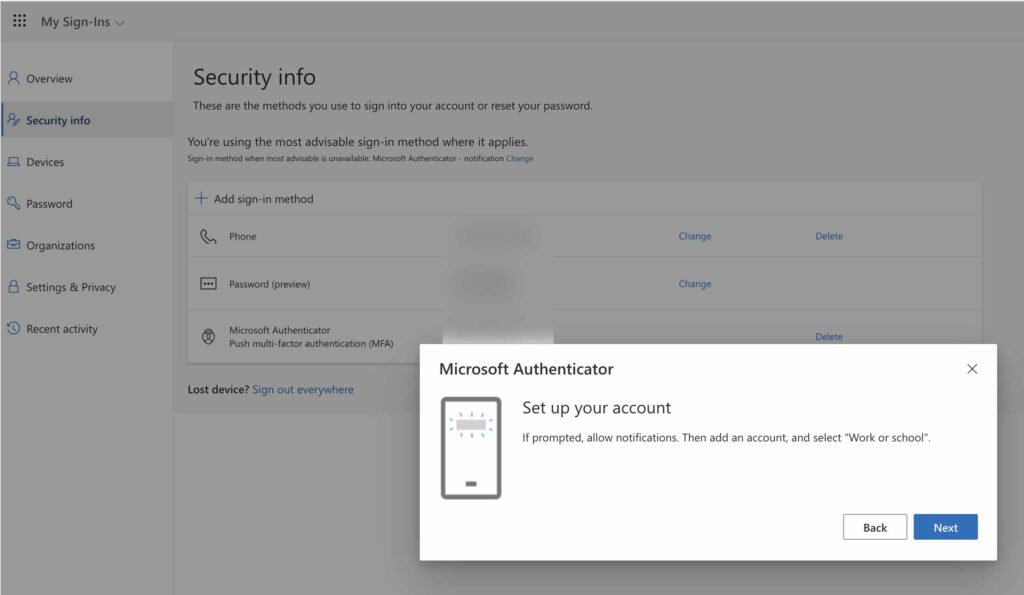
「設定」-「Head and Footer」を選択
「Head, Footer and Post Injections」を導入したら、「設定」を見てみます。すると以下の通り「Head and Footer」というメニューができています。
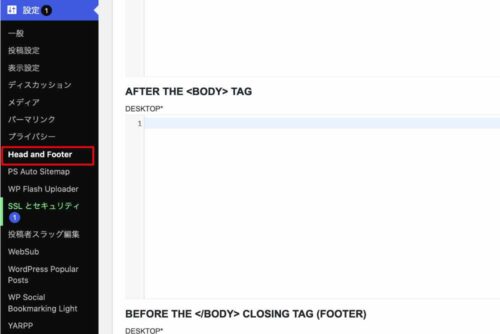
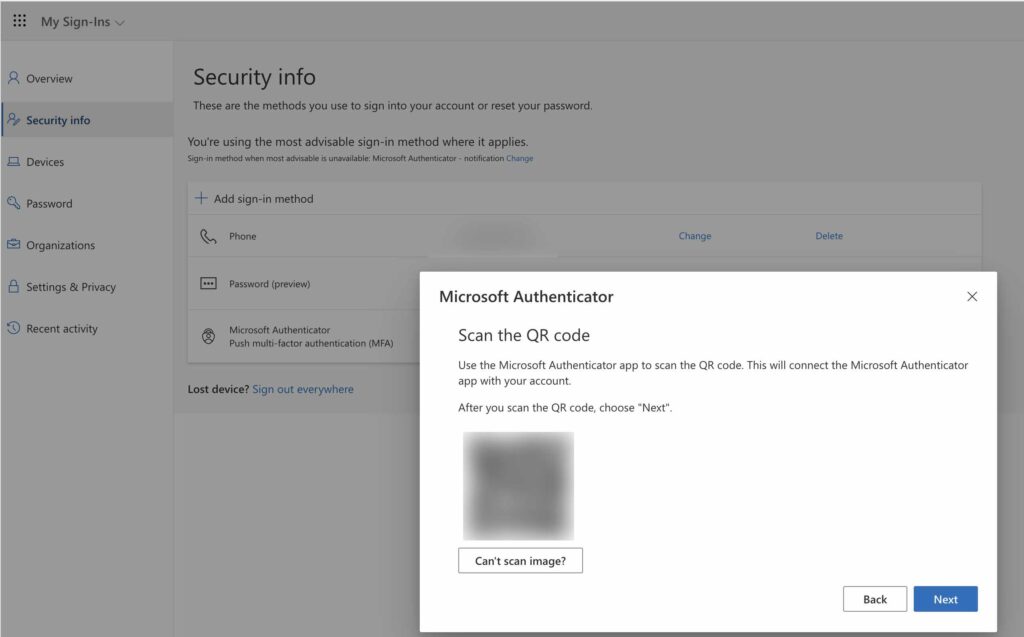
Posts タブの「AFTER THE POST CONTENT」にタグを追記
「Head and Footer」を選択すると以下の画面が表示され、たくさんのタブが表示されていますが、この中から「Posts」タブを選択します。
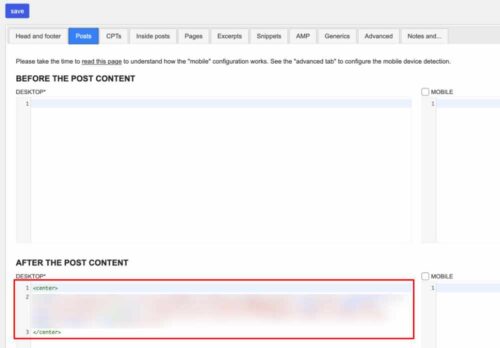
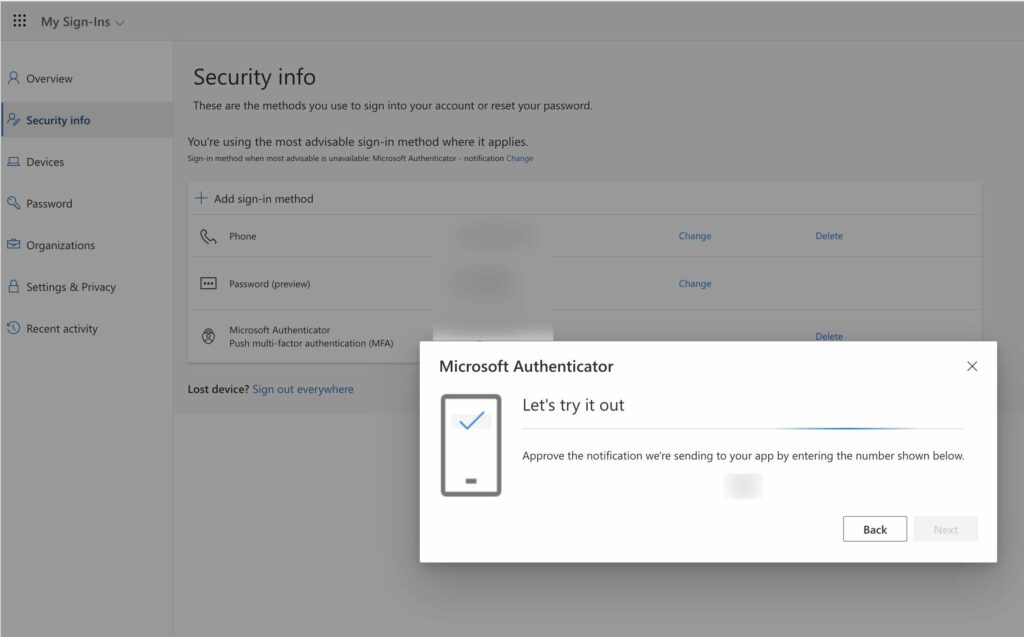
この「Posts」タブの中の「AFTER THE POST CONTENT」に赤枠の通り広告用のタグをコピぺすると自分で書いた記事の直下に広告が表示されます。
なお、広告用のタグを<center>〜</center>で括ると、いい感じに画面の中央に広告が表示されると思います。
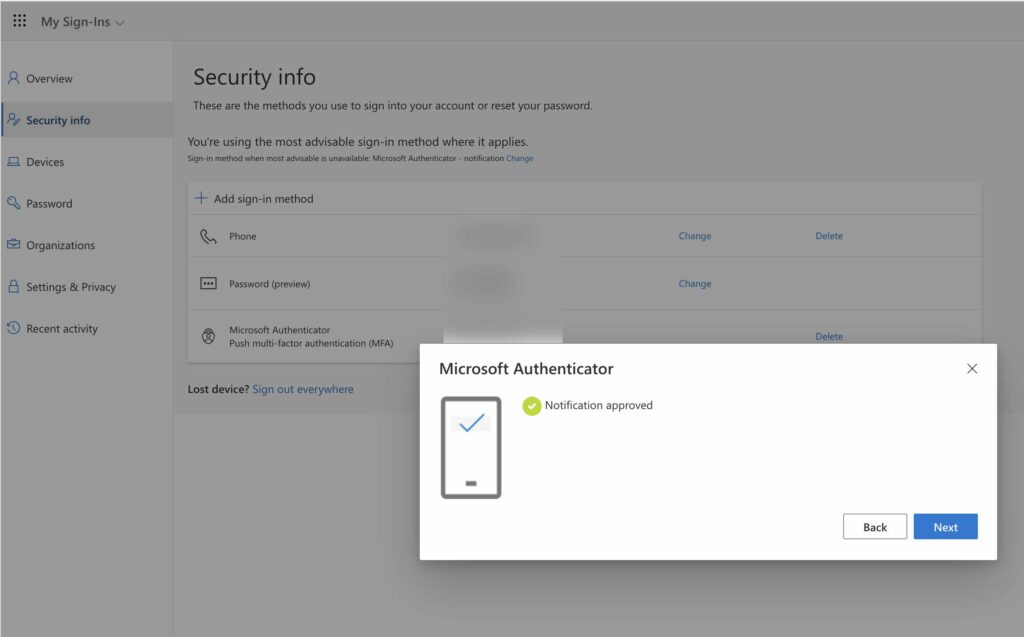
広告が自分の記事の直後に表示されていることを確認
最後に広告が正しく表示されていることを確認しましょう。
できれば記事にあった広告をページ毎に設定するのが効果的だとは思いますが、たくさん記事があるとなかなか難しいと思いますので、こういった方法もありなのでは無いかと思います。